Less Writing, More Talking

TL;DR: With accuracy rates above 95%, latency approaching human levels, and contracts moving into production, we remain bullish on the future of voice technology within the enterprise.
Then: Lots of promise, but an unclear path to mainstream adoption
In early 2024, when we conducted our first deep dive into Voice AI, we were excited by the promise of a new era of enterprise-grade voice intelligence and strongly believed that this space was ripe for disruption.
Now: Near-human-level interactions being achieved and market demand booming
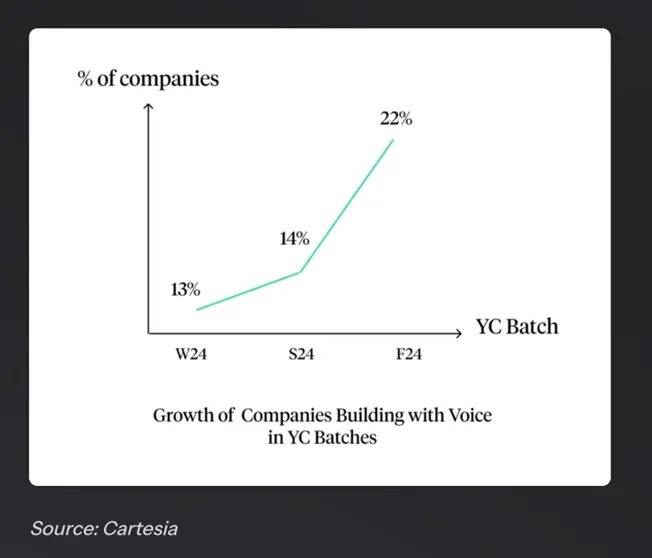
Fast forward just over a year, and the voice AI space has not just matured — it has exploded. The funding going to Voice AI businesses grew 8× YoY to $2.1 billion in 2024, fuelled by the advances in AI speech models, which are getting closer to human-like interactions.
This has led to a surge in the deployment of AI-powered voice agents across both consumer and enterprise environments. Today’s voice agents can engage in complex, multi-turn conversations, understand context, and execute tasks across systems — from triaging customer support tickets to automating internal workflows. Advancements in real-time speech recognition, natural language understanding, and the integration of voice interfaces into everyday tools and platforms are enabling this.
At this trajectory, voice agents could be on the path to becoming a default interface for interacting with software in sectors ranging from healthcare to financial services.
Getting technical — how can a business use this?
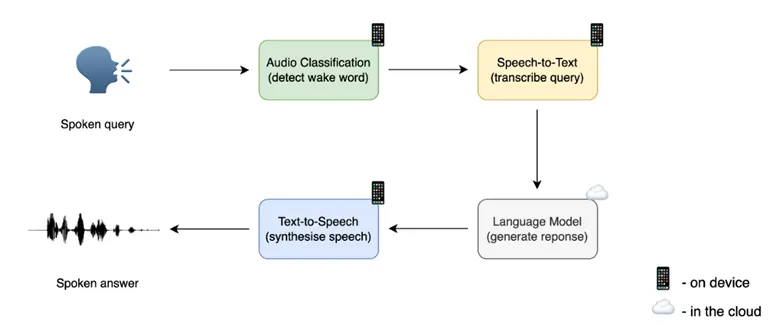
Today, businesses connect to model providers through APIs, to integrate voice AI within their products. This includes both STT (speech-to-text) and TTS (text-to-speech) providers.
Most of these use an encoder-decoder architecture (seq2seq). The encoder would be how you convert the data (audio or text), and the decoder how you process the data to generate an output (text or audio). The output will be audio if it’s a TTS product, and text if STT. This structure offers sufficient context to get an accurate output, is flexible regarding the lengths of output/input, and both processes (encoding/decoding) can be optimized separately.
The players
Over the last two years, the TTS market, both B2C and B2B, has matured quickly, with clear category leaders like Eleven Labs or Cartesia emerging. The STT market is moving more slowly and remains fragmented, with several actors still competing in both the real-time and async markets. Apart from large tech companies like Amazon or Google, the main players in this market are Deepgram, AssemblyAI, Gladia, and Speechmatics. Eleven Labs has recently expanded their product to STT to provide a full infrastructure platform to their customers, allowing them to build voice agents using Eleven Labs for both STT and TTS.

Middleware emerging…
This layer is gaining traction quickly — businesses here (Vapi or Retell, for instance) abstract the difficulty behind building voice agents, allowing businesses to build agents more efficiently and without the need to connect to model provider APIs. While this approach has been successful with SMEs and mid-market companies, it is unclear whether enterprises will use these abstraction layers or decide to keep more control over the underlying layer and work directly with infrastructure providers.
Use-cases remain broad and aspirational
From note-taking to debt collection to customer support… each offers a substantial market opportunity to make voice the way we interact with machines instead of text.
We hear a lot about the long-term vision to build what Jarvis was to Iron Man, but realistically, how far are we from that future?
Today, models are offering a latency close to human-like interactions, with best-in-class benchmark results reaching around 150 ms. Those benchmarks do not give an accurate reflection of a real conversation with accents, numbers, background noise… but still give an idea of how much the models have improved.
What’s holding us back? The little things matter.
95%+ accuracy sounds high, but the 5% missing can be what matters most in many use-cases. Take customer support in the insurance industry — the model needs to get the policy number and first/last name of the customer perfectly. Without an accurate claim number, the agent won’t be able to solve the problem… instead, it will just give a near-accurate transcript of an angry customer to support!
These gaps are, in our view, what’s preventing voice AI from scaling faster in an enterprise context. However, given the velocity of improvement, they should be solved in the coming 12–24 months.
For example, our portfolio company Gladia has been able to clear the accuracy hurdle for that tricky numbers use-case — specifically across multiple languages and with low latency.
Leading businesses are seeing these results and positioning themselves where the puck is heading.
What a business prioritises — quality, cost, latency… — will depend on their individual use-case and needs.
But if the value does not come from quality/latency, then where does it sit?
Our thesis is that the performance of model providers will converge over time, and that defensibility comes from something different.
First, we believe that most of the value won’t sit with the technology itself, but within how you interface your platform with the customers’ existing systems, in order to capture and leverage the data as effectively as possible.
Take the customer support example: voice platforms would need to be integrated with CRMs and customer support platforms like Intercom or Zendesk, in order to add context to the requests and offer the most relevant answer to the customers based on past interactions.
The second value-add piece comes from all the add-on features infrastructure providers can build — whether this is a security layer, an evaluation feature, a governance layer… or, in the case of STT providers, sentiment analysis, topic classification, chapterisation, keyword extraction…
Voice platforms should not only enable voice-based interactions, but also provide insights on conversations to enrich the systems of record of their customers, while allowing them to build enterprise-grade voice-based products.
We believe we’re still at the start of the Voice era, and remain convinced of its long-term potential. We’re happy investors in Gladia (audio intelligence platform) and Reality Defender (deepfake detection), and would love to chat if you’re building in this space.